本文概览
请求-响应循环
概括:志愿者通过客户端连接到项目服务器(也就是说,如果有人想让别人为自己的项目贡献算力,那么就需要自己有一个服务器,并且自己设置任务如何拆分),服务器下发任务,志愿者完成后把结果传回去。
- 客户端定期向服务器发送rpc请求,询问有没有新任务/报告已经完成的任务
- 如果有新任务,服务器则把任务描述和必要的输入文件打包,通过http下载给客户端
- 客户端下载后在本地计算,完成后把结果上传回服务器
- 服务器验证无误后给客户端增加积分
额外设计
- 由于是客户端主动发起http请求,所以防火墙不会阻挡
- 如果服务器宕机,客户端设计了指数退避机制,避免广播风暴
帐户管理器(AM,用户端的中控)
- 如果想参加多个项目。只需在AM上注册一个帐号,勾选多个项目,AM自动的动态调整项目分配(依照用户设置,比如只在晚上运行 or 某项目优先级最高)
用户偏好
- 关键词偏好:志愿者可对一系列领域关键词选择是或否,表达对特定领域 or 项目的偏好。
- 物理、天文、亚洲……
- 计算偏好
- 限制CPU使用率
- 任务运行时段
- 磁盘内存网络的占用
- ……
硬件异构性的应对方案
- 对于同一个科学应用,需要项目方编译出多个不同版本,每个版本对应一种特定的处理器+OS组合
- win + x64
- linux + arm64
- ……
- 客户端上报自己的平台环境,服务器根据此给客户端发送不同版本的程序
- 更精确的控制:特定版本的cpu
plan class(由项目方定义)
输入:电脑的硬件和软件描述
输出
- 这个App版本是否能在该电脑上运行?
-
如果能跑,大概需要多少CPU、GPU资源
-
资源运算的峰值 FLOPS大概是多少?
比如一个plan class可以规定,“只有具备了NVIDIA RTX 30系列显卡且驱动大于某个特定版本的电脑才能运行这个APP版本”
Job
app+输入文件的集合
job属性设计:flops估计(用于预测运行时间)、最大flops、ram工作集大小、磁盘使用上限、关键词
Instance
任务执行的具体单元。一个job被分成多个instance
结果验证
志愿者的设备匿名且不可控
复制验证、同质冗余、自适应复制、项目方提供自定义验证函数
运行时隔离
安装程序创建一个专门的用户来运行boinc,保护用户原有的文件
客户端还要能控制应用程序的生命周期(暂停、恢复、终止)
boinc实现了一套基于消息传递的机制,通过共享内存来实现客户端和应用程序之间的通信、发送控制指令、接收状态信息
图形化程序
让用户感到酷炫,展示计算进度
实在没有合适的APP版本怎么办
boinc包装器
提交任务
高级特性
- 对于运行时间很长的任务可以提前上传中间结果
- 如果某个job需要很大的输入文件,且这个文件会被很多instance用到,那么局部性调度——将任务分配给已经下载了这个文件的志愿者,减少网络传输。
-
由于不同电脑存在性能差异,服务器可根据主机性能历史,动态分配调整instance的大小,确保每个instance的运行时间都是差不多的,例如1小时
- 对于非cpu密集型任务的优先级调度
参数设计
一个任务除了“成功返回“,还有很多其他结局:程序崩溃、硬件故障、恶意篡改、任务丢失……
- delay_bound( J ): 任务截止时间,超时则视为失败并重试。
- min_quorum( J ): 验证所需成功实例数,多数一致则采纳。
- init_ninstances( J ): 初始并行实例数,加速达成验证。
- max_error_instances( J ): 最大允许失败次数,防止程序崩溃。
- max_success_instances( J ): 最大允许成功次数,防止非确定性结果。
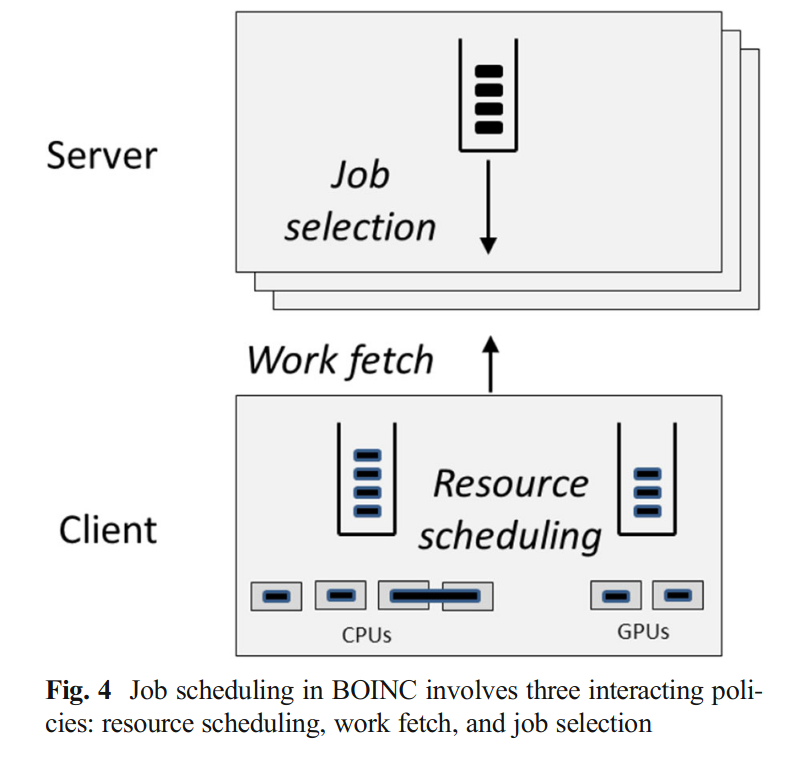
调度策略(重要)
虽然是项目服务器进行集中任务分发,但各种调度发生在客户端。因为是用户主动进行请求,客户端要多少,服务器给多少,然后服务器进行预估时间与验证正确性。
策略:
- 客户端:决定当前运行哪些任务
- 客户端:决定何时、向哪个项目请求更多任务。
-
服务器:根据客户端请求,选择发送哪些任务
目标:
- 最终完成所有任务。
-
最大化吞吐量 (避免空闲、按时完成、使用最佳版本)。
-
遵循志愿者的资源分配和偏好。
客户端:决定当前运行哪些任务
- 资源
- 类型:CPU 、 GPU
- 利用率: 估计峰值 FLOPS (Whetstone for CPU, vendor estimate for GPU)
- 任务队列:
- 类型:待运行、执行中、挂起、抢占的任务
- 资源需求: 每个任务对 CPU/GPU 的使用量
- 内存占用: 估计 RAM 工作集大小 (
est_wss(J)) - 目标
- 可行性: 任务集合满足资源和内存约束
- 最大可行性: 在可行的前提下,尽可能多地运行任务
- 策略:加权轮询 (WRR)
- 权重(或叫优先级):是动态的,根据志愿者为不同项目分配的资源份额以及近期使用情况进行调整
- 时间切片: 默认每 1 小时重新计算优先级,运行高优先级项目的任务,目的是防止某个项目长期独占资源
- 针对截止时间,进行剩余运行时间估计
- 静态估计: 任务 FLOP 估计 / 服务器 FLOPs/s 估计
- 动态估计: 当前运行时间 / 已完成比例
- 把以上二者加权平均(或单纯平均)
- WRR 模拟: 定期模拟 WRR 执行,预测哪些任务会错过截止时间
- EDF (最早截止时间优先)
- 如果预测到截止时间错过,则采用 EDF 策略
优先级排序
- 预测会错过截止时间的任务 (EDF)
- GPU 任务优先于 CPU 任务
- 时间切片中间或未检查点的任务
- 使用更多 CPU 的任务
- 项目调度优先级高的任务
客户端:决定何时、向哪个项目请求更多任务
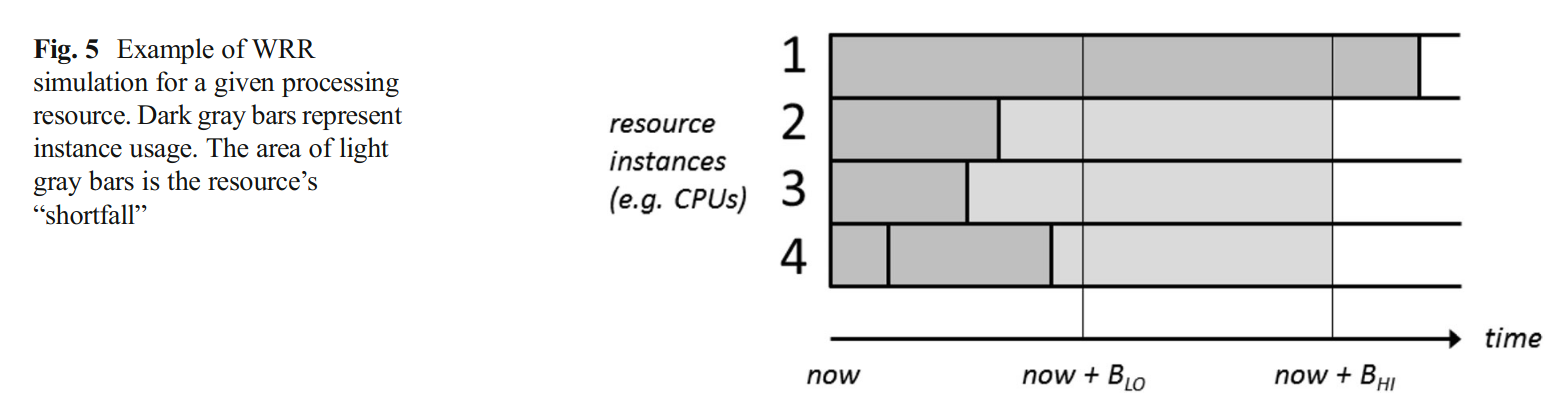
缓冲区存一些已经下载好的任务,留着一会用。缓冲区有B_LO (下限), B_HI (上限)。触发条件: 当前缓冲工作量 < B_LO 时,向项目服务器请求补充工作
- 这样设计的原因:
- 保证网络断开、服务器宕机或项目无任务时,仍有足够工作保持资源忙碌
- 每次 RPC 获取尽可能多的任务,减少 RPC 频率,也就减轻了项目服务器压力
WRR 模拟用于估计缓冲区持续时间,以便缓冲缺口计算,(T(A)是资源实例 A 的预计使用时间)
\operatorname{shortfall}(R)=\sum_{i n s t a n c e s A \text { of } R} \max \left(0, B_{H I}-T(A)\right)
工作请求参数
- 缓冲缺口,服务器应发送足够工作以填补缺口。req_runtime(R)
-
空闲资源实例数,服务器应发送能充分利用这些空闲资源的任务。 req_idle(R)
-
队列中待处理任务的预计剩余运行时间,用于估计新任务完成时间。queue_dur(R)
-
可获取性 (Fetchability) 项目
P是否能提供资源R的任务 (非暂停、非回退、有可用版本、用户允许)。
工作获取逻辑
- WRR 模拟,判断是否需要补充工作。
- 按项目调度优先级降序扫描。
- 找到第一个满足条件的项目
P,向其发送工作请求。 - “搭便车” (Piggybacking): 在其他 RPC 请求中,如果
P是最高优先级且可获取资源R的项目,也请求工作。