本文概览
看到一个写得还不错的笔记,但是只写了前两章,我来续上一续。
论文:
3 算力建模
建模是调度和交易的基础。
3.1 度量目标:评估资源池有多少算力、用户的任务要用多少算力
- 算力分类:逻辑计算能力(代表:CPU,单位:TOPS)、并行计算能力(代表:GPU,单位:flops)、神经网络计算能力(代表:DPU、NPU、TPU,单位:flops) (Deep learning Processing Unit,而不是智能网卡那个DPU)
- 计算资源并不是决定服务效果的唯一因素。还有:缓存资源(缓存大小)、网络资源(网络数据包延迟变化PDV、每秒帧数FPS)、服务资源(上层封装的微服务、AI应用中模型的推理延迟、编解码能力、训练深度模型时的吞吐量)
3.2 基础设施算力建模
(由3.1可知,虽此处称“算力”,但那些其余资源或服务质量参数也要考虑在内)
- 基础设施很多,XPU系列就能列出一串,他们的架构各不相同。所以还是把能提供相似服务的处理器分成一撮——逻辑计算能力、并行计算能力与神经网络计算能力。
- 《算力网络中面向业务体验的算力建模》中提出了一个公式,在(1)。也给出了一个度量算力的例子。
- 最后说到随着DL的发展,日常收集收集数据,直接扔进黑箱也不是不行。
3.3 任务需求算力建模
- 目标是将用户的需求映射为一个具体的数,比如多少FLOPS。
- however,延迟难以预测(注:没看懂为什么扯到延迟去了)。但好在可以通过把一个任务发给不同的计算节点来实测。
- 接下来给出一堆数学式子的含义是,盯着式子(2),左边是实测延迟,右侧是与计算资源相关的参数以及一些系数。把系数拟合出来,就得到映射关系了。
3.4 算力等级分级
因为新型的、面向用户的智能应用主要需要浮点计算能力,所以就用它作为分级依据。
| 级别 | 计算能力范围 | 例子 |
|---|---|---|
| 一级 | >1PFLOPS | 视频渲染 |
| 二级 | 10TFLOPS ~ 1PFLOPS | 训练 |
| 三级 | 500GFLOPS ~ 10TFLOPS | 推理 |
| 四级 | <500GFLOPS | 语音识别 |
4 算网中的信息感知与通告
4.1 感知用户信息
- 位置感知。又是随着AI的发展能够预测。
- 任务需求感知。
- 基本任务特征
- 计算性能目标
- computing capacity requirements
- computing capacity requirements
- 存储性能目标:比如有的模型训练需要大内存
- 网络性能目标
- 算法性能目标
4.2 感知计算节点信息
需要感知的计算节点信息主要包括计算节点的位置、计算资源状态(包括计算能力类型、总计算能力和剩余计算资源)、存储资源状态(包括存储容量、剩余存储资源、存储能力、存储质量等)、网络接口带宽、可用服务、服务ID和服务定位器以及每个计算节点的负载。
4.3 感知网络链路信息
4.4 通告信息(三种方式)
集中
分布式
文献36属于科普类,如果需要讲故事时可着重阅读。第2部分(算力网络控制技术)里大意是:CFN资源信息全网扩散啦,本地生成路由表啦,虚拟的服务ID为目的地址啦,这可真是太好了!可一系列细节是没人提啊,所以我们的设计中,路由器只做本地资源汇集,路由表靠中央控制器统一计算下发。(其实也没说清楚)
目前对于CFN协议关于汇聚、IGP与BGP之间的交互以及AS之间的交互细节研究尚未成熟,所以为了算力网络运行的可行性,我们需要对算力网络进行统一的管理
我们考虑到,相比路由器,计算资源节点数量庞大,如果每一个计算资源节点都需要与算力网络控制器进行通信,那么对于算力网络控制器来说压力过大。所以最终我们采用的是路由器继续承担计算资源信息搜集的责任,详细的集中式控制架构下工作流程如图4所示。
文献37值得一看。背景方面,互联网由约 5万 个AS组成,它们通过BGP协议交换路由信息。在每个 AS 内部,通过内部 BGP(iBGP)会话进行信息重分布,以便为外部目的地选择最佳出口点。现有的主要 iBGP 重分布机制包括 iBGP 全网状、路由反射器和 BGP 联盟,但它们要么保证选择最佳出口点,要么提高可扩展性,无法兼顾。研究内容方面,提出了一种新的基于 AS 的 IGP 拓扑的 iBGP 重分布方法 iBGP2,通过让路由器仅向邻居宣传满足特定条件的路由,使 iBGP 宣告的分发遵循 IGP 拓扑,从而兼顾路由选择的最优性和可扩展性。实验方面,通过 ns-3 模拟器和 Quagga 路由套件进行了开源实现。扩展方面,文中提到 iBGP2 可以扩展以支持多个并行的 IGP 路由平面,这为未来根据不同的网络性能指标(如带宽、延迟等)进行出口点选择提供可能。
混合
两种实现方式
目前,学者们认为存在两种主要的信息公告实现方式。第一种机制基于层次化扩展路由。待公告的信息被划分为粗粒度信息和细粒度信息。粗粒度信息依据扩展的 BGP 协议在两个边缘网络之间进行公告,而细粒度信息则由边缘网络中的节点依据扩展的 OSPF 协议进行维护。第二种机制基于新型路由协议。设计了一个新的计算路由层,以主流分布式一致性协议(如 raft [39]/paxos [40])的思想为基础,实现分布式订阅公告或定向更新。这种方法可以与路由协议解耦,从而降低计算资源变更对路由规则收敛的影响。此外,我们还可以根据实际网络特性和用户需求对分布式一致性协议进行改进,使其更加实用,例如适应链路质量 [41, 42]、高可用性 [43]、低延迟高吞吐量场景 [44] 等。
文献39、41-43是raft算法及其相关展开。关于raft,可看此翻译。
文献44值得一看,背景方面,传统共识协议(如 Paxos)性能受限,成为分布式系统中的瓶颈。但随着可编程网络交换机的出现,其性能可与专用硬件相媲美,为在转发平面中实现共识协议提供了机会。设计方面,P4xos 将 Paxos 协议中的提议者、接受者和学习者等角色分别部署在数据中心的不同网络设备上(如主机、叶交换机、聚合交换机和脊交换机),通过 P4 语言在交换机 ASIC 中实现 Paxos 协议的逻辑,利用可编程转发平面加速共识过程,减少消息在网络中的传输次数和主机处理延迟。中心有两个,一是在交换机的asic中实现paxos的关键逻辑,提高性能,二是弱化网络行为假设,这种弱化适用于更广泛的网络环境和应用场景,不需要针对特定网络条件进行专门的定制和优化,降低协议部署维护成本,便于在不同的分布式系统中推广和应用。
5 智能资源管理
5.2
- 选择目标计算节点
- 任务拆分
- 如果需要跨域拆分,怎么拆
- 域内怎么拆
优化目标:最小化延迟、减少能耗、提高处理器利用率
优化策略:凸优化、博弈、DRL。
调度会在云边端的各个地方执行,端卸载到端、端到边、端到云、边到云。在研究初期,假定任务无法分割,但现在就可拆分了。
5.3 服务编排
讲的是云原生,即服务与底层完全解耦。特别说到可以把服务部署在容器当中,如果用户需要不同的算力服务,那么按需开启关闭。
5.4 智能资源管理
6 算力路由与转发
只讲了SRv6的工作方法。
在最后说,随着AI技术的发展XXXXXX(ai for 一切)
7 算力网络平台
讲交易,基于区块链技术的可信算网交易平台是实现商业化的重要部分。
K8S做集群管理
8 测试平台
讲的是作者在22年的一个工作,叫《Computing Power Network: A Testbed and Applications with Edge Intelligence》,是workshop,只有两页(很多东西没讲清楚),然后把主要文段在这篇survey中又抄了一遍。个人感觉这篇workshop内容不是很饱满(因为他们的Cloud只是监控,不承载计算任务),图画的很清楚。
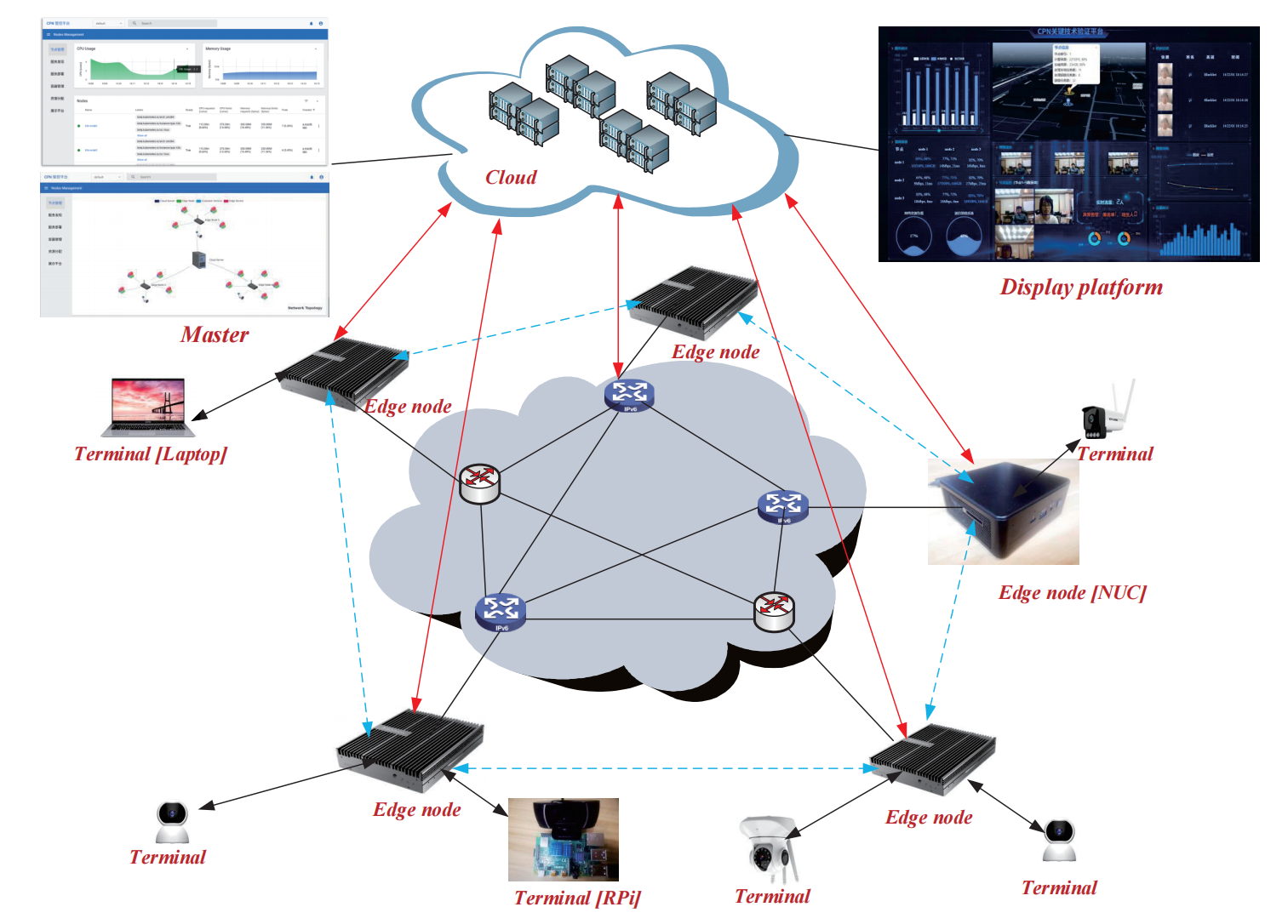
内容是实现了三层架构(cloud-Edge-Terminal)的边缘计算调度器。调度算法是利用二分图匹配思想,一边是任务,另一边是算力资源。架构自上而下看,中心控制器部署在cloud,负责汇总任务与计算资源(然后生成一张叫ComNet的有向无环带权图,是一个全局的计算资源视图,图的节点就是承载计算任务的Edge node,图的边是链路能力)、监控网络性能、集群管理。算力节点在Edge node,发布任务的是Terminal。调度算法的实现是通过四个微服务:
- 计算感知
- 使用Prometheus监控工具,定期采集边节点的ComNet数据。包括节点资源(计算资源量、存储资源量、实时资源利用率)、链路质量(链路带宽、TCP建立延迟)
- 计算通告
- 基于ZeroMQ协议和分布式一致性算法,把信息同步给其他边节点。并将信息合并到ComNet。每个节点都要了解整个网络的计算资源分布。
- 计算建模
- 根据神经网络模型,依据ComNet与预测试数据集的响应延迟,评估边节点的计算能力。而不是去直接看内部参数。最后要建立从ComNet到延迟的映射。(猜测意思是之后只通过任务类型就能预测用时?)
- 计算卸载
- 利用二分图匹配思想,建立一个二分图,此外改进了二分图算法,具体改进不详。(猜测边权是延迟,然后计算权最小但匹配对数最大的匹配方案)
(workshop介绍完毕)
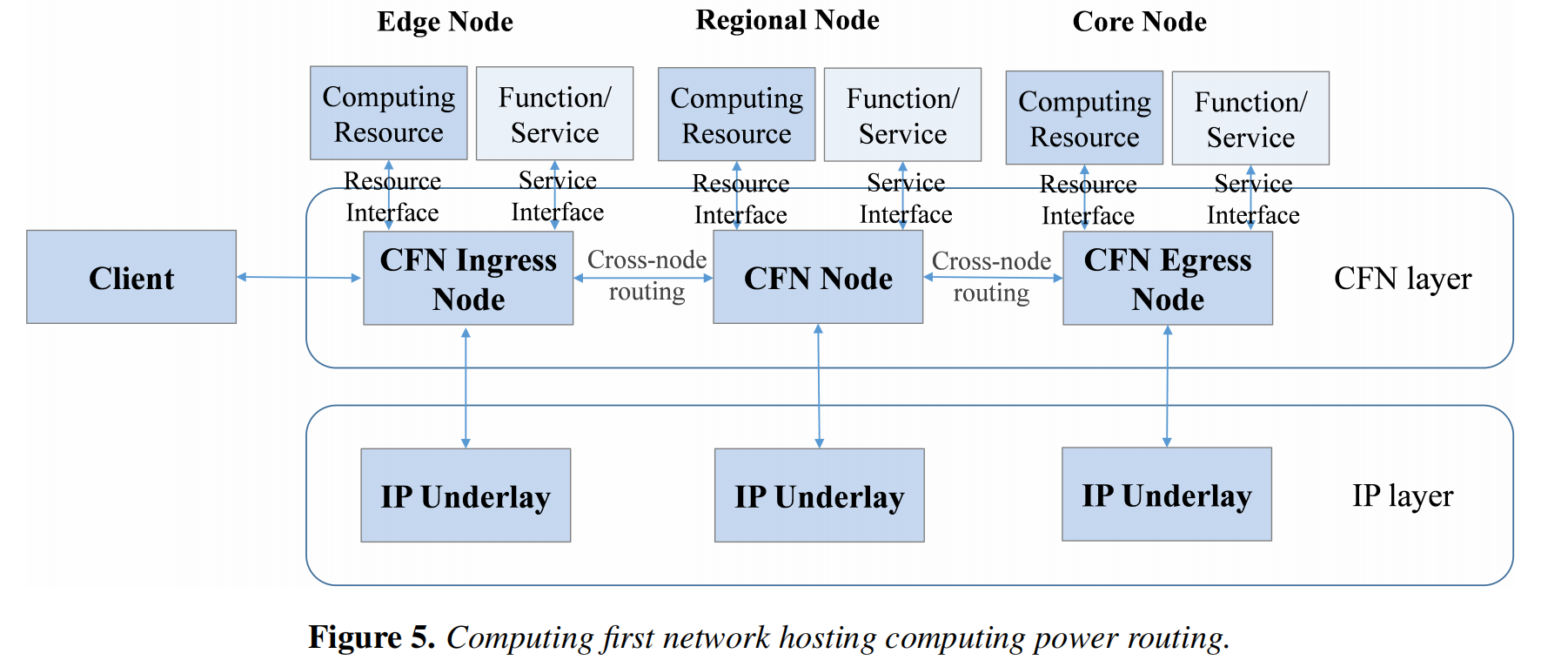
此workshop只有1篇reference,也就是本文文献38,唐雄燕,曹畅的《Computing Power Network: The Architecture of Convergence of Computing and Networking towards 6G Requirement》(2021).其中提到的CFN(计算优先网络)实现算力路由和动态调度。这是与我相关的。要注意这个CFN本身就是一个overlay网,但只在IP层之上,还算比较靠下的。
9 应用场景
终端计算感知网络(TCAN),想把终端设备的算力都用起来(BOINC的故事)
云游戏、车联网
10 能给算力网络赋能的技术
列举了:MEC(workshop讲的就是这个)、SDN(集中控制)、NFV(将网络功能软件化)、网络切片(为不同应用创建独立定制化的网络通道)、Docker(部署微服务)、SRv6、AI(用于调度、优化、决策等本文中一切出现“随着AI技术的发展”字样的CPN组成部分)
11 开放性挑战与未来方案
列举了:算力建模(当下没有统一度量标准,要找寻更全面反映算力特征的因素,可能借助机器学习)、信息同步(节点信息公告的规模有限,解决方法:IP层之上的新层次用于信息公告/设计更好的协议用于信息快速发布与收敛)、用户经常移动(怎么让任务跟着迁移)、由于要感知则要传送海量数据使网络拥塞(那就要让网络设备能够处理一部分数据才行)、能耗、算网如何结合确定性网络技术、可信计算服务、计价策略。
(完)