二者区别
UCX 是底层通信的基础框架(点对点通信),而 UCC 是构建在 UCX 等底层库之上的上层集体通信库(集体通信)。
UCX目标是提供统一接口,让上层(如MPI、UCC)高效利用各种硬件资源。比如,InfiniBand、RoCE、TCP/IP、共享内存等。(UCC、MPI的下层不一定是UCX。 UCX是它们实现时可以选择的其中一种底层通信库,但并不是唯一选择)
UCC专注于集体通信模式,具有后端无关性。可以动态选择 UCX、NCCL、SHARP(InfiniBand的网络内计算)、MPI 甚至 CUDA 等作为执行操作的“引擎”。对于使用者来说,只需要调用如 ucc_collective_init 和 ucc_collective_post 等高级API即可。此外,UCC 有一个调度组件,可以根据操作的类型、数据大小、网络拓扑等信息,智能地选择最快、最合适的算法和后端来执行。
UCC是一个比较新的框架,22年4月正式发布1.0版本,在24年HOTI会议上发表论文《Unified Collective Communication (UCC): An Unified Library for CPU, GPU, and DPU Collectives》(统一集体通信UCC:一个面向 CPU、GPU 和 DPU 集体的统一库)。
集体通信
核心特点
- 涉及一组进程:不止两个进程。
- 全局操作:操作的结果或过程依赖于组内所有成员。
- 隐式协调与同步:操作本身通常包含了进程间的协调,有时甚至会引入同步点(即所有进程都到达某个点后才能继续)。
以MPI为例,常见的集体通信操作有
| 操作名称 | 功能描述 |
|---|---|
| Broadcast(广播) | 一个进程(根进程)将相同的数据发送给组内的所有其他进程。 |
| Scatter(散播) | 一个进程将一块数据的不同部分分别发送给组内的所有进程。 |
| Gather(收集) | 一个进程从组内所有其他进程那里接收数据,并按照进程号顺序组合成一块数据。 |
| All-Gather(全收集) | 每个进程都拥有一个数据块,执行操作后,所有进程都拥有全部数据块的集合。 |
| Reduce(规约) | 将组内所有进程的数据通过一个操作(如求和、求最大值、求最小值等)合并为一个结果,存放在一个指定进程(根进程)中。 |
| All-Reduce(全规约) | 执行Reduce操作,但结果分发给所有进程。这是机器学习和科学计算中最常用的操作之一。 |
| Barrier(屏障) | 组内所有进程在此同步,必须所有进程都到达屏障后,才能继续向下执行。 |
| All-to-All(全交换) | 每个进程都向所有其他进程发送不同的消息,同时也从所有其他进程接收消息。 |
UCC论文(HOTI’24)
Unified Collective Communication (UCC): An Unified Library for CPU, GPU, and DPU Collectives
[推荐阅读](UCC简介 | RedBlog)
[演讲回放]([HOTI2024] 统一集合通信UCC_哔哩哔哩_bilibili)
背景
集体通信用于进程间的数据交换与同步,无论是在HPC领域还是DL领域都非常重要。但现有通信库各自优化专有硬件。UCC希望统一 CPU、GPU、DPU 上的集体通信、支持多种编程模型、整合软件与硬件传输机制。
概述
UCC 的实现精髓在于其模块化和分层调度,这使得 UCC 成为一个既能统一接口,又能充分发挥异构硬件性能的通信库。

UCC 组件架构如图所示,使用尽可能接近底层的方式实现了集合通信,并向上层应用提供了调用的接口。UCC对集合通信操作的实现分为两层,TL即Transport Layer,主要负责针对不同的底层通信协议实现集合通信操作最基本的功能,如UCP、NCCL、SHARED Memory等。CL层为Collective Layer,在TL层的基础上进一步丰富了其功能,如Hier组件实现了分层的集合通信操作。
设计目标
- 通用性(既支持MPI等传统HPC负载,又支持PyTorch等AI/DL负载)
- 兼容性(既能使用UCX传统点对点通信等软件传输,也能支持如[ref14]的硬件传输)
- 支持并行与重叠(通过推进多个独立的集体操作来实现并行,允许通信与计算重叠来提供重叠能力)
- 支持异构硬件(CPU、DPU、GPU,集体通信可以由异构硬件中的任何一个发起,或者数据可以驻留在主内存或设备内存中)为支持此设计目标,库的集体调用模型应同时支持紧耦合调用模型(CPU 线程调用并执行集体操作)和松耦合调用模型(CPU 线程调用集体操作,而 GPU 流执行集体操作)。
- 可扩展性(就是必须模块化)
设计原则

为实现前述目标,UCC 的设计围绕三个核心概念:抽象、属性 、 操作,每个抽象有自己的属性与操作
- 抽象 代表了 UCC 库的基本资源和能力。它们封装了集体操作所需的计算资源、网络资源和网络端点。在规范中,它以
ucc_{抽象名称}的形式表示。 - 属性 代表了抽象的语义。它们使用户能够定制抽象以满足各种工作负载的需求。在 UCC 中,它以
ucc_{抽象名称}_params_t的形式表示。 - 操作 提供了对这些抽象执行动作的接口。这些操作包括创建和销毁抽象以及更新语义。
UCC 中的主要抽象包括五个:库、上下文、团队、端点 和 执行引擎
- UCC 库
- UCC 库是集体通信库所需所有资源的封装。对于一个给定的应用程序,通常只需要一个库实例。
- 属性:UCC 库的属性包括:
- 线程模型:UCC 支持多种线程模式(
THREAD_SINGLE,THREAD_MULTIPLE,FUNNELED),以适应 MPI 和 OpenSHMEM 编程模型。 - 同步模型:UCC 支持两种同步模型——同步(
SYNC)和异步(NO_SYNC),以满足 MPI、OpenSHMEM 和统一并行 C 编程模型的需求。 - 支持的集体操作:Barrier、Broadcast、All-gather、Gather、Scatter、Allreduce、AlltoAll 和 Reduce,以及这些集体操作的向量变体。
- 线程模型:UCC 支持多种线程模式(
- 操作:UCC 库 的操作包括初始化、创建和销毁库对象。
- UCC 上下文
- UCC 上下文 封装了本地网络资源,包括软件网络资源(例如,虚拟接口、注入队列、连接端点、共享内存缓冲区)和硬件网络资源(例如,全局资源树)。此抽象有助于管理分配给集体操作的资源。
- 属性:上下文可以创建为独占类型或共享类型,独占类型提供更高性能,共享类型节省资源。
- 操作:UCC 上下文操作包括初始化、创建和销毁上下文对象。
- UCC Teams
- UCC Teams 封装了用于集体操作的组资源,类似于 MPI 通信器或 OpenSHMEM Teams 。
- 属性:UCC Teams 的属性包括:
- (1) 排序模型,它定义了参与集体操作的进程如何调用该集体操作(有序或无序)。
- (2) 团队的参与者。
- (3) 为资源分配而设置的未完成集体操作的数量。
- (4) 集体操作所需的内存资源。
- (5) 同步模型。
- 操作:UCC 团队 的操作包括提交团队创建请求、测试创建是否完成以及销毁团队对象。
- UCC 端点
- UCC 端点代表了团队中参与者的唯一标识符,允许将端点绑定到并行编程模型中的索引,例如 OpenSHMEM 处理元素(PE)、MPI 排名、操作系统进程 ID 或线程 ID。
- 属性:端点可以是连续的或非连续的。
- 执行引擎(EE)
- 执行引擎抽象了执行集体操作的计算资源(CPU 或 GPU)。通过与 EE 的事件驱动机制进行交互,可以在调用线程和执行线程之间存在高延迟时实现高效交互。
- 属性:UCC 支持的 EE 类型包括:CUDA STREAM、ROCM STREAM 和 CPU THREAD。
- 操作:EE 操作包括创建和销毁,以及事件管理操作,例如 SET、GET 和 ACK。
通过采用这些设计原则,UCC 提供了一个灵活而高效的解决方案,能够满足多样化的工作负载和编程模型的需求。
实现
UCC 的实现像一个高度模块化的工具箱,其核心设计是组件化架构。
核心与组件
- CORE:面向用户的 API 在
ucc.h头文件中提供。这些接口在 UCC 版本发布之间保持一致性并向后兼容。该 API 被实现为 UCC 的 CORE,其余功能则作为组件实现。 - 组件:UCC 的大部分功能是作为组件实现的,主要分为CL层、TL层、内存组件、拓扑组件。
- Collective Layer (CL):CL层组合多个TL层,以提供编程模型所需的、与传输无关的集体实现。它决定集体操作的执行策略。例如,Basic CL 实现直接调用底层传输;Hierachical CL 实现则像先在小团队内完成计算,再在团队代表间汇总,适合大规模系统。
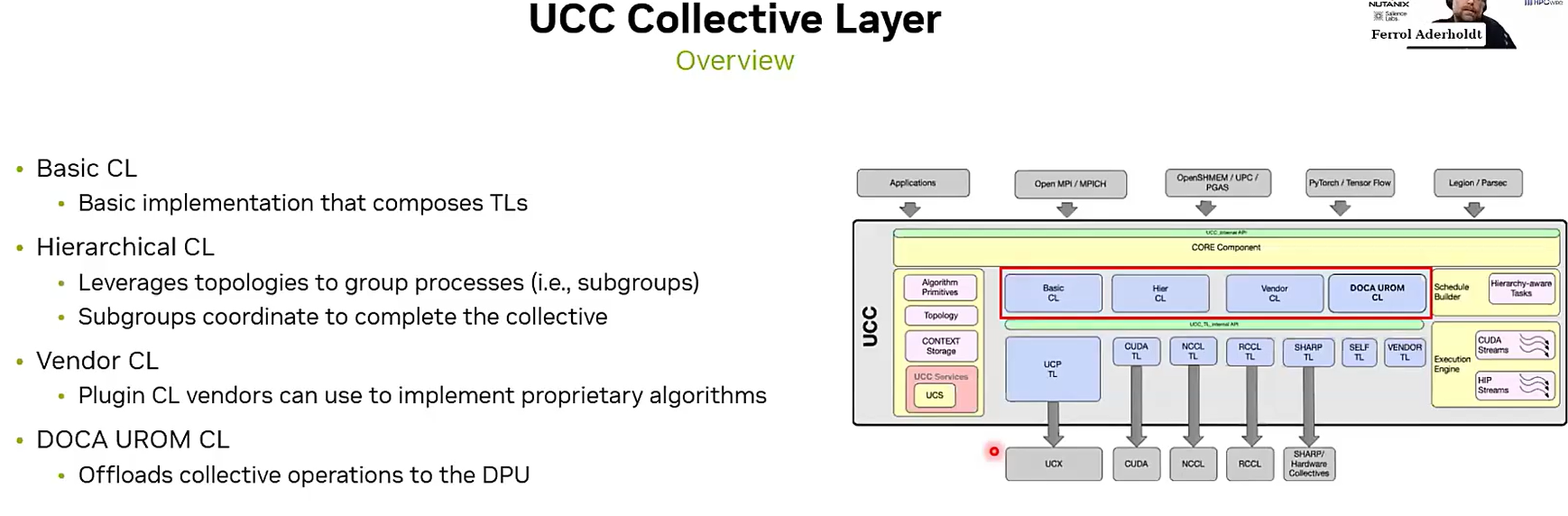
- Team Layer (TL):这是与具体通信硬件对接的一层。UCC 通过不同的 TL 来调用不同的通信库:
- UCP TL:使用 UCX 库,适用于 CPU 和多种网络(如 InfiniBand)。
- NCCL TL:调用 NVIDIA 的 NCCL 库,专门用于 NVIDIA GPU。
- SHARP TL:使用支持在网络交换机内计算(在网计算)的硬件。
- CUDA TL:针对单台服务器内 GPU 间的通信。

- Memory Component:支持 CPU/GPU 内存操作
- Topology Component:用于分层集体中的端点分组
- Collective Layer (CL):CL层组合多个TL层,以提供编程模型所需的、与传输无关的集体实现。它决定集体操作的执行策略。例如,Basic CL 实现直接调用底层传输;Hierachical CL 实现则像先在小团队内完成计算,再在团队代表间汇总,适合大规模系统。
集体操作的执行流程
概念:一个复杂的【集体操作】(如分层 Allreduce)被拆分成多个小的【任务】(如:节点内规约 -> 节点间全规约 -> 节点内广播)。这些任务及其依赖关系构成一个【调度计划】。UCC 内部通过【进度队列】来管理这些任务,实现并行推进和依赖处理。
UCC 支持阻塞、非阻塞和持久化的调用与执行模型。通过组合以下接口来提供对此的支持:ucc_collective_init, ucc_collective_post, ucc_collective_test, ucc_collective_finalize。
- ucc_collective_init:指定计划。程序提供参数(如数据地址、操作类型)。该接口根据这些信息智能地选择(稍后介绍)最合适的CL层、TL层和算法,并规划好执行步骤,生成一个【调度计划】。
- ucc_collective_post:开始执行计划。UCC 开始执行调度计划中的【任务】。
- ucc_collective_test:程序可以随时询问操作是否完成。UCC会回复完成了或者还在做。
- ucc_collective_finalize:操作完成后,释放资源。
关于“智能的选择”:论文的目标是证明这种统一设计的可行性和优势,具体的选择机制官方文档中或许有(或源代码)。
核心任务是为一类特定的集体操作选择一个 “集体层 – 团队层” 的组合。论文中明确提到的选择层次包括:
- 选择集体层:是使用 基础、分层、供应商 还是 UROM 实现策略。
- 选择团队层:根据上面选定的策略,进一步选择使用哪个具体的传输库,例如 UCP、NCCL、SHARP、CUDA、RCCL 等。
论文中提到的决策因素有:数据大小、Team规模、硬件位置、拓扑、可用资源、工作负载类型。
论文例子:一个典型的分层 Allreduce 集体操作将包括以下调度计划和任务:
- 任务 1: Intra-node Reduce using TL/UCP
- 任务 2: Inter-node Allreduce using TL/SHARP
- 任务 3: Intra-node Broadcast using TL/UCP
- 对 GPU 的特别支持
通过执行引擎和触发式API优化 GPU 通信
为了让 GPU 也能高效发起和参与集体操作,UCC 引入了执行引擎和触发式提交的概念。
- 执行引擎:抽象了 GPU 的计算上下文(如 CUDA 流)。
- 触发式提交:程序可以将集体操作”绑定”到一个特定的 GPU 流上,并指定一个事件作为启动信号。当这个事件发生时,集体操作会自动在 GPU 上开始执行。这实现了计算与通信的精细重叠,避免了 GPU 空闲等待。
- 对 DPU 的卸载
通过客户端-服务端模型实现向 DPU 的卸载
UCC 可以通过 UROM 组件将集体操作卸载到 DPU 上执行。
- 工作方式:主机端的 UCC 库作为客户端,将集体操作的命令发送给在 DPU 上运行的 UROM 服务。
- 流程:DPU 上的服务接收命令,用自己的 UCC 实例在 DPU 之间完成整个集体操作,最后将结果通知主机。
- 好处:将主机的 CPU/GPU 从通信任务中解放出来,专注于计算,提升整体效率。