ATC19:R2P2: Making RPCs first-class datacenter citizens
分类: 论文精读
Towards Optimal Rack-scale µs-level CPU Scheduling through In-Network Workload Shaping
找到研究场景,确定研究问题,然后在环境里做减法,减到每个机制都是必要的,且动机可查——这是要费大力气去想的。
继续阅读“Towards Optimal Rack-scale µs-level CPU Scheduling through In-Network Workload Shaping”
MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale
OSDI24:MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale
继续阅读“MAST: Global Scheduling of ML Training across Geo-Distributed Datacenters at Hyperscale”
Switches for HIRE: resource scheduling for data center in-network computing
ASPLOS ’21:Switches for HIRE: resource scheduling for data center in-network computing
继续阅读“Switches for HIRE: resource scheduling for data center in-network computing”
ODOS-MPI:高性能处理器友好型智能网卡计算/通信内核卸载
DPU=SmartNIC+通用处理,其中的通用处理核给HPC领域带来一些新机遇。但DPU作为新的硬件,支持它的编程框架是没有的。所以这两篇使得OpenMP支持DPU编程。DPU作为能单独运行Linux操作系统的协处理器进行任务卸载。
一些思考
DPU的使用必须涉及并发。而不能像使用GPU那样,把任务卸载后等它干完再返回得数,这是无意义的,因为失去性能。
DPU未来能扮演什么角色(也就是DPU能卸载什么)?已知作为网络处理器,能卸载网络协议,那么能否把计算任务卸载?
两篇论文
- ODOS:如何让代码在DPU上跑起来
- ODOS-MPI:如何让代码在DPU上跑起来的同时,还能进行MPI通信
| 项目 | SC23 (ODOS) | SC25 (ODOS-MPI) |
|---|---|---|
| 目标 | 首次实现OpenMP卸载到DPU | 在ODOS基础上支持MPI通信卸载 |
| 贡献 | 实现了基础的OpenMP卸载机制(ODOS) | 扩展为MPI+OpenMP混合卸载(ODOS-MPI) |
| 技术支持 | LLVM + DOCA SDK | 同左 + 扩展Open MPI以支持异构通信 |
| 应用场景 | 纯计算任务卸载(如SPEC ACCEL) | 支持通信+计算并发执行(如miniWeather) |
| 性能提升 | 验证可行性,性能接近MPI基线 | 在真实应用中实现>18%加速 |
故事从ODOS讲起
ODOS 论文
ODOS 全称是 OpenMP DOCA Offloading Support。顾名思义,它是一个在LLVM/OpenMP框架内实现的、利用NVIDIA DOCA SDK来实现OpenMP卸载功能的后端。(生态绑定)
它的核心目标是,让程序员能够像写GPU卸载代码一样,使用#pragma omp target等指令,将代码段卸载到DPU上运行,而无需关心底层的复杂通信和异构细节。
在ODOS出现之前,如果想利用DPU的计算能力,主要有两种方式,但都有明显缺点:
- 低级别DOCA编程:
- 直接使用DOCA SDK提供的API。
- 问题:过于底层、复杂,对领域科学家(如物理学家、气象学家)来说编程门槛极高,不利于广泛应用。
- MPI多节点编程:
- 将DPU视为一个独立的、能力较弱的计算节点,在上面启动MPI进程。(下图a)
- 问题:编程模型不自然。程序员需要显式管理主机和DPU之间不同的MPI Rank,处理两者之间巨大的性能差异,并手动进行数据发送/接收,如同在编写分布式程序。
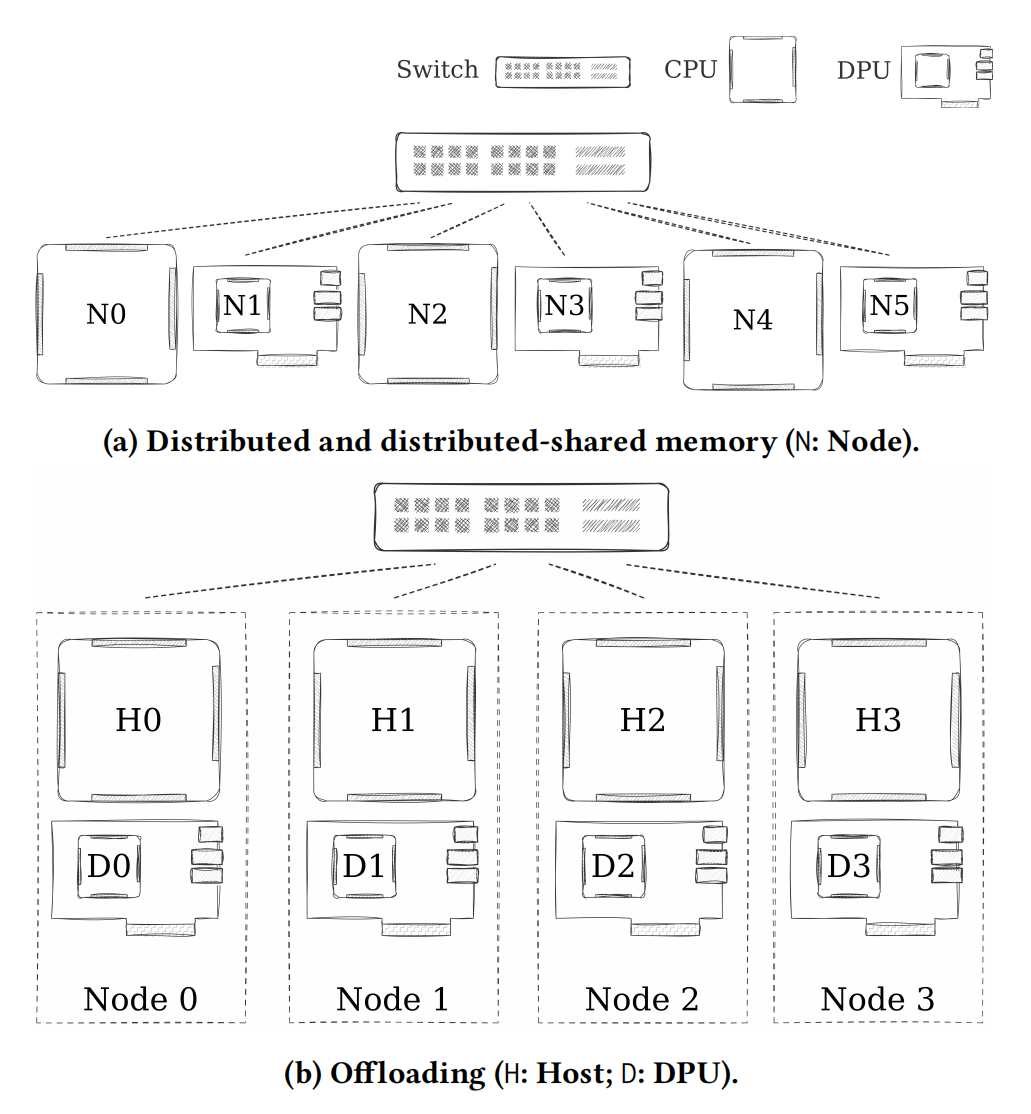
ODOS的价值就在于提供了第三种方式——使用高级、标准化的OpenMP模型,将DPU视为一个本地协处理器,极大地简化了编程。正如上图b,DPU和主机拥有相同Rank号。
ODOS由三个部分组成。
一、交叉编译的修改
负责将包含#pragma omp target的源代码编译成可以在DPU上运行的“胖二进制文件”。
主机通常是x86架构,而DPU是ARM架构。因此需要进行交叉编译,这是我们已经知道的。但是,标准的LLVM交叉编译通常假设目标设备使用与主机相同或类似的基础库。DPU在“独立主机模式”下运行一个完整的、独立的Linux操作系统,拥有自己的一套库和头文件(即独立的sysroot)。所以ODOS修改了Clang和链接器包装器,使其能够同时处理主机(x86_64)和目标设备(aarch64)两个不同的sysroot,从而正确地将DPU所需的库链接到胖二进制文件中。
二、编写OpenMP BlueField插件
是主机端的运行时库,让 OpenMP 运行时能够使用 BlueField DPU 这个硬件设备。
OpenMP运行时有一个抽象的“设备接口”。GPU有它的插件(比如用于NVIDIA GPU的插件),FPGA也有它的插件。但在ODOS之前,DPU没有自己的插件。这个OpenMP BlueField插件是连接标准OpenMP运行时和DOCA的桥梁。其职责包括设备发现、加载二进制文件、数据管理、执行控制、
对上层 OpenMP 运行时隐藏 DPU 的复杂细节(如 DOCA API、PCIe 通信)。特定于 BlueField DPU(及其 DOCA SDK)。
三、DOCA OpenMP服务进程
这是一个运行在DPU本身上的守护进程,接收并执行来自主机插件的请求。
- 它作为一个服务端,通过DOCA CC监听主机的连接。
- 它接收主机发送过来的二进制映像,并使用
dlopen和dlsym将其动态加载为共享库。 - 为了运行目标区域,它使用了
libffi库。这是因为目标函数的参数在编译时对服务是未知的,libffi允许在运行时动态地创建和调用函数。
请注意,ODOS的目标硬件(DPU)与传统的卸载目标(GPU)在核心架构上是不同的:
| 特性 | GPU | DPU (如 BlueField-3) |
|---|---|---|
| 核心类型 | 大量(数千个)轻量级计算核心 | 少量(16个)功能完整的ARM CPU核心 |
| 并行模式 | 大规模并行:适合在数千个核心上同时执行相同的简单操作。 | 多核并行:适合在十几个核心上执行更复杂、可能有一定分支的任务。 |
所以,最佳并行策略是不同的。GPU偏好的大规模并行语义,而 DPU偏好的传统多核并行语义。所以在具体编程时,GPU:
#pragma omp target teams distribute parallel for map(to: A[0:N], B[0:N]) map(from: C[0:N])
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
DPU:(少了teams distribute,少创建很多很多线程)
#pragma omp target parallel for map(to: A[0:N], B[0:N]) map(from: C[0:N])
for (int i = 0; i < N; i++) {
C[i] = A[i] + B[i];
}
以上,ODOS是仅仅卸载计算的代表,卸载内容是纯计算内核(无MPI调用),缺点是通信仍需主机CPU处理,通信成为瓶颈。主机在通信时无法计算,DPU在计算时主机可能空闲。
那么能不能将一个既包含计算又包含MPI调用的完整代码块(内核)一起卸载到DPU上执行?就来到今年的《ODOS-MPI》了。
ODOS-MPI 论文
ODOS-MPI 编程模型有如下特点:
- 将OpenMP的taregt命令所引导的offload region运行在BlueField DPU之上(ODOS已完成)
- 在offload region之中,使得MPI也能运行(ODOS-MPI的核心)
- 利用MPI_Info 的提示信息决定,操作的目标在DPU上还是在主机之上(操作比如send/put)
在ODOS基础上,ODOS-MPI进行如下的新增工作(第三列),主要目的是通信和计算的双卸载:
| 领域 | ODOS | ODOS-MPI |
|---|---|---|
| 编译器与工具链 | 扩展LLVM/Clang,支持DPU交叉编译,生成胖二进制文件。 | 复用 |
| OpenMP运行时插件 | 创建了OpenMP BlueField插件,实现设备发现、代码加载、数据传输。 | 扩展该插件,使其能识别并处理包含MPI调用的目标区域,与新的MPI运行时交互。 |
| DPU端服务 | 创建了DOCA OpenMP服务,用libffi执行纯计算函数。 |
增强该服务,使其能与DPU上的MPI运行时交互,支持在目标区域内调用MPI函数。 |
| MPI集成 | 完全不涉及。卸载区域内不能有MPI调用。 | 核心新工作: • 双MPI运行时:在主机和DPU上分别初始化MPI,并让它们共享Rank号。 • 异构通信:通过扩展UCX,增加主机-设备通信端点。 • HETEROGENEOUS提示符:新发明的MPI_Info键,用于明确指定异构通信路径。 |
| 编程模型语义 | 定义了标准的OpenMP卸载语义,仅用于计算。 | 核心新工作: • 定义了在OpenMP卸载区域内调用MPI的语义(如 nowait与MPI_Barrier的交互)。• 定义了异构通信(主机↔设备)和同构通信(设备↔设备)的规则。 • 定义了集体操作的限制(必须在同一“侧”发起)。 |
| 同步模型 | 使用OpenMP的taskwait进行同步。 |
扩展同步模型:结合MPI_Barrier和OpenMP taskwait,实现主机与设备间的跨域同步。 |
ODOS-MPI初始化两个独立的MPI运行时:
- 主机MPI运行时:运行应用程序主进程
- DPU MPI运行时:作为后台服务处理卸载请求
两个运行时使用相同的MPI Rank编号,为程序员提供统一的消息传递视图。
异构通信支持:通过扩展Open MPI的UCX组件,ODOS-MPI实现了:
- 端点扩展:在原有主机-主机端点基础上,增加主机-设备端点
- 通信模式:
- 同构通信:主机↔主机 或 DPU↔DPU
- 异构通信:主机↔DPU(通过
MPI_Info提示符控制)
小结:设计与实现一个编程模型时需要考虑什么
抽象层次
计算模型
数据模型
并发模型
集成
硬件抽象
工具链